

数仓基础概念概述
数据仓库概念由比尔.恩门于1990年提出,主要是将OLTP系统存储的数据,经数据仓库特有的理论以及架构体系,进行系统的分析整理。
数仓目的
构建面向分析的集成化数据环境,为企业提提决策支持。
数仓的作用
- 提供集成的结构化数据
- 解决从数据库中获取信息的问题
数仓的特点
数仓的特点是面向主题的,集成的,稳定的,反向历史变化的。
数仓知识点
数仓作为数据的搬运工,本身不产生数据,也不消费数据,数据来源于外部,也开放给外部系统。
随着大数据系统的发展,机器学习以及人工智能的崛起,数仓已经不仅仅作为为企业提供决策支持的商业智能BI,也是大量机器学习以及人工智能算法的底层支持。
数仓特点详解
面向主题的 Subject Oriented
数据仓库是⽤来分析特定主题域的,所以说数据仓库是⾯向主题的。
电商业务主题域:
- 交易域
- 商品域
- 用户域
- 财务域
社交业务:
- 内容域
- 会员域
- 互动域
- 交易域
集成的 Integrated
数据仓库集成了多个数据源,同⼀主题或产品相关数据可能来⾃不同系统不同类型的数据库、⽇志⽂件等。
稳定的 Non-Volatile
数据⼀旦进⼊数据仓库,则不可改变。数据仓库的历史数据是不应该被更新 的,同时存储的稳定性较强。
反映历史变化的 Time Variant
数据仓库保存了⻓期的历史数据,这点是相对OLTP的数据库⽽⾔。因为性能考虑后者通常保存近期的热数据。
数据仓库核心组件
数据仓库的核心组件有四个:源数据库,ETL,数据仓库,业务应用。

业务系统
业务系统包含各种源数据库,这些源数据库既为业务系统提供数据支撑,同时也作为数据仓库的数据源(注:除了业务系统,数据仓库也可从其他外部数据源获取数据)
ETL
ETL分别代表:提取extraction、转换transformation、加载load。其中提取过程表示操作型数据库搜集指定数据,转换过程表示将数据转化为指定格式并进行数据清洗保证数据质量,加载过程表示将转换过后满足指定格式的数据加载进数据仓库。数据仓库会周期不断地从源数据库提取清洗好了的数据,因此也被称为”目标系统”
业务应用
和操作型数据库一样,数据仓库通常提供具有直接访问数据仓库功能的业务应用,这些应用也被称为BI(商务智能)应用
ETL详解
ETL工作的实质就是从各个数据源提取数据,对数据进行转换,并最终加载填充数据到数据仓库维度建模后的表中。只有当这些维度/事实表被填充好,ETL工作才算完成。接下来分别对抽取,转换,加载这三个环节进行讲解:
抽取(Extract)
数据仓库是面向分析的,而操作型数据库是面向应用的。显然,并不是所有用于支撑业务系统的数据都有拿来分析的必要。因此,该阶段主要是根据数据仓库主题、主题域确定需要从应用数据库中提取的数。
具体开发过程中,开发人员必然经常发现某些ETL步骤和数据仓库建模后的表描述不符。这时候就要重新核对、设计需求,重新进行ETL。正如数据库系列的这篇中讲到的,任何涉及到需求的变动,都需要重头开始并更新需求文档。
转换(Transform)
转换步骤主要是指对提取好了的数据的结构进行转换,以满足目标数据仓库模型的过程。此外,转换过程也负责数据质量工作,这部分也被称为数据清洗(data cleaning)。数据质量涵盖的内容可具体参考这里。
加载(Load)
加载过程将已经提取好了,转换后保证了数据质量的数据加载到目标数据仓库。加载可分为两种L:首次加载(first load)和刷新加载(refresh load)。其中,首次加载会涉及到大量数据,而刷新加载则属于一种微批量式的加载。
多说一句,如今随着各种分布式、云计算工具的兴起,ETL实则变成了ELT。就是业务系统自身不会做转换工作,而是在简单的清洗后将数据导入分布式平台,让平台统一进行清洗转换等工作。这样做能充分利用平台的分布式特性,同时使业务系统更专注于业务本身。
数据集市(data mart)
数据集市可以理解为是一种”小型数据仓库”,它只包含单个主题,且关注范围也非全局。
数据集市可以分为两种,一种是独立数据集市(independent data mart),这类数据集市有自己的源数据库和ETL架构;另一种是非独立数据集市(dependent data mart),这种数据集市没有自己的源系统,它的数据来自数据仓库。当用户或者应用程序不需要/不必要/不允许用到整个数据仓库的数据时,非独立数据集市就可以简单为用户提供一个数据仓库的”子集”。
数据湖概念
数据仓库开发流程
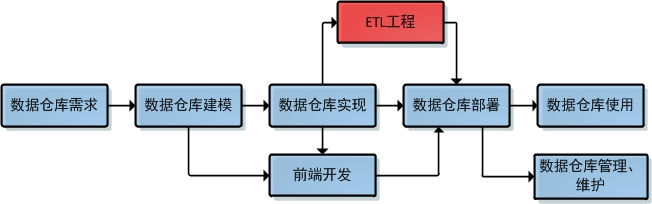
上图可以看出数据仓库开发最为耗时部分在ETL工程部分。因为该环节要整理各大业务系统中杂乱无章的数据并协调元数据上的差别,所以工作量很大。在很多公司都专门设有ETL工程师这样的岗位,大的公司甚至专门聘请ETL专家。
小结
在大数据时代,数据仓库的重要性更胜以往。Hadoop平台下的Hive,Spark平台下的Spark SQL都是各自生态圈内应用最热门的配套工具,而它们的本质就是开源分布式数据仓库。
在国内最优秀的互联网公司里(如阿里、腾讯),很多数据引擎是架构在数据仓库之上的(如数据分析引擎、数据挖掘引擎、推荐引擎、可视化引擎等等)。不少员工认为,开发成本应更多集中在数据仓库层,不断加大数据建设的投入。因为一旦规范、标准、高性能的数据仓库建立好了,在之上进行数据分析、数据挖掘、跑推荐算法等都是轻松惬意的事情。反之如果业务数据没梳理好,各种脏乱数据会搞得人焦头烂额,苦不堪言。







