

5000字长文解析:带你解读阿里大数据建设方法论OneData
前言
onedata体系方法论最早发起于阿里,随着数据时代的全面到来,数据中台产品的完善,很多公司在建设自己的产品和方法论体系时,也都有参考和借鉴此观点,本文将围绕阿里早期业务情况以及数仓建设遇到的问题,结合作者的一些想法,分享一下这个概念,如有不足,敬请谅解。
onedata体系方法论产生的背景

上面这张图非常清晰的展示了2014年前后淘宝的的产品线矩阵,从这里我们可以了解到早期阿里是以淘宝业务线为主,1688及淘宝国际站为辅的方式,慢慢衍生出广告、天猫、本地生活、聚划算等众多业务,从而构建了自己的完整电商生态矩阵。
产品矩阵中不同的产品往往代表不同的业务,每个业务都会产生自己的数据,同时也有着自己独特的产品形态。早期的阿里数仓体系建设对数据的管理还是较为独立的,按照业务的角度去建设,甚至一个业务就是一个小型数据仓库,早期还好,灵活多变可以快速的响应业务需求、从而支撑业务决策。但随着数据增长、业务场景更加复杂,也产生了很多问题。
数仓建设常见问题整理
作者总结了部分部分较为常见的问题,这些问题不仅仅阿里有,甚至在现在很多公司中也是深受困扰,急需解决。
1、数据孤岛、烟囱式重复建设
缺少公共数据的提炼和汇总,出现烟囱式重复建设,同时也加剧了数据孤岛的问题。
2、数据不一致
孤岛式的建设,缺少统一的组织及方法论,指标口径不统一、数据表级字段名不一致,数据有二义性
3、缺少统一模型规范
当不同业务之间有数据交叉的场景时,为了尽快响应业务需求,直接从其他业务明细层甚至原始数据层获取数据,不同的研发团队不同规范,造成模型设计不统一,复用性差。
4、效率差、响应慢
缺少公共聚合数据的沉淀和积累,每次新的需求都需要5-7天以上的研发,无法服用,产出时效差,数据质量低,资源消耗成本高居不下
onedata方法论的定义
针对上面的问题,阿里制定了 OneData 作为内部数据整合及管理的方法论。期望在这一方法论下,构建统一、规范、可共享的全域数据体系,避免数据的冗余和重复建设,规避烟囱式建设和不一致性,从而快速响应需求,对外提供高质量服务。

我理解的话,onedata 是通过完善的规范定义,同时结合数据中台产品,进行指标的统一定义及梳理,进一步标准化建模,从而保证数据只加工一次的目标实现。
onedata体系架构
这里整理了一个经典的阿里onedata体系架构,对这一体系的阐述我觉得还是很全面的。甚至随着中台概念的兴起,现在很多数据中台产品都是以这一架构的内容,进行数据产品的研发。
例如:网易有数的数据中台产品中有EasyIndex指标系统对指标进行管理,EasyDesign实现模型设计等;阿里有MaxCompute。

业务板块:
根据业务属性,将业务划分出几个相对独立的板块,使业务板块之间的指标或业务重叠性较小
规范定义:
结合行业的数据仓库建设经验和阿里数据自身特点,设计出的一套数据规范命名体系,规范定义将会被用在模型设计中;
模型设计:
以维度建模理论为基础,基于维度建模总线架构,构建一致性的维度和事实(进行规范定义),同时,在落地表模型时,基于阿里自身业务特点,设计一套规范命名体系。
OneData 在公司中怎么建设,实施流程有哪些呢?
指导方针: 首先,在建设大数据数据仓库时,要进行充分的业务调研和需求分析。这是数据仓库建设的基石,业务调研和需求分析做得是否充分直接决定了数据仓库建设是否成功。其次,进行数据总体架构设计,主要是根据数据域对数据进行划分;按照维度建模理论,构建总线矩阵、抽象出业务过程和维度。再次,对报表需求进行抽象整理出相关指标体系,使用OneData工具完成指标规范定义和模型设计。最后,就是代码研发和运维。
业务调研
数据仓库是要涵盖所有业务领域,还是各个业务领域独自建设,业务领域内的业务线也同样面临着这个问题。所以要构建大数据数据仓库,就需要了解各个业务领域、业务线的业务有什么共同点和不同点,以及各个业务线可以细分为哪几个业务模块,每个业务模块具体的业务流程又是怎样的。业务调研是否充分,将会直接决定数据仓库建设是否成功。
需求调研
了解了业务系统的业务后并不代表就可以进行实施了,还需要和业务运营人员或数据分析师等,去沟通需求,了解他们有什么数据诉求,一般比较直观的就是一个个报表。
需求调研的途径有那些呢?
一是根据与分析师、业务运营人员的沟通(邮件、IM)获知需求;二是对报表系统中现有的报表进行研究分析。
通过需求调研分析后,就清楚数据要做成什么样的。很多时候,都是由具体的数据需求驱动数据仓库团队去了解业务系统的业务数据,这两者并没有严格的先后顺序。
数据域划分

数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。业务过程可以概括为一个个不可拆分的行为事件,如下单、支付、退款。为保障整个体系的生命力,数据域需要抽象提炼,并且长期维护和更新,但不轻易变动。在划分数据域时,既能涵盖当前所有的业务需求,又能在新业务进入时无影响地被包含进已有的数据域中或者扩展新的数据域。
构建总线矩阵,探查业务过程
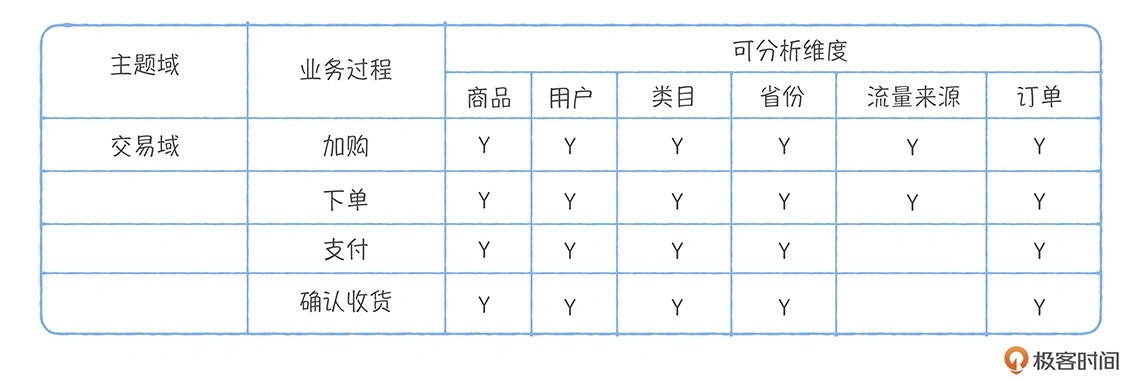
在进行充分的业务调研和需求调研后,就要着手构建总线矩阵了。在这一步我们需要做两件事情:
1、明确每个数据域下有哪些业务过程;
2、业务过程与哪些维度相关,并定义每个数据域下的业务过程和维度。
规范定义(标准化定义)
在数仓建设进行开发前,就要进行数据的规范定义。通过以业务的视角进行数据的统一和标准定义后,从而确保计算口径一致、算法一致、命名一致,后续的数据模型设计和ETL开发都是在此基础上进行的。在这一规范也可以说是标准化的定义下,进一步保障数据域、业务过程,以及在数据域、业务过程之下的指标、实体属性等的命名和定义。。
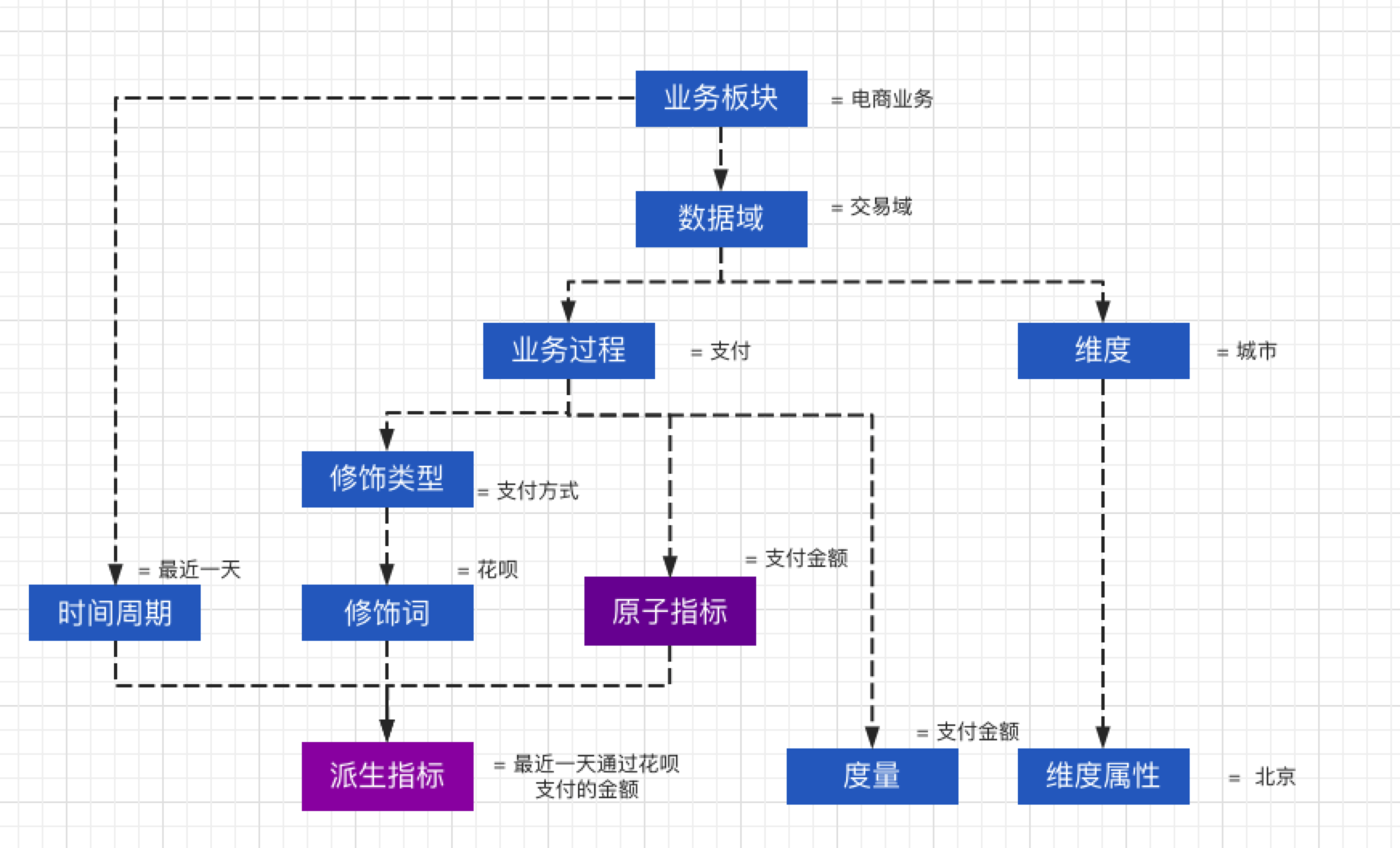
名词定义
数据域:面向业务的大模块,不会经常变。比如我们公司有环贸快版打版服务、亿订电商业务、供应链业务等等大的业务模块类似产品线。
| 名词 | 名词定义 |
|---|---|
| 业务过程 | 如电商业务中的下单、支付、退款等都属于业务过程 |
| 时间周期 | 就是统计范围,如近30天、自然周、截止到当天等 |
| 修饰类型 | 比较好理解的如电商中支付方式,终端类型等 |
| 修饰词 | 除了维度以外的限定词,如电商支付中的微信支付、支付宝支付、网银支付等。终端类型为安卓、IOS等 |
| 原子指标 | 不可再拆分的指标如支付金额、支付件数等指标 |
| 维度 | 常见的维度有地理维度(国家、地区等)、时间维度(年、月、周、日等) |
| 维度属性 | 如地理维度中的国家名称、ID、省份名称等 |
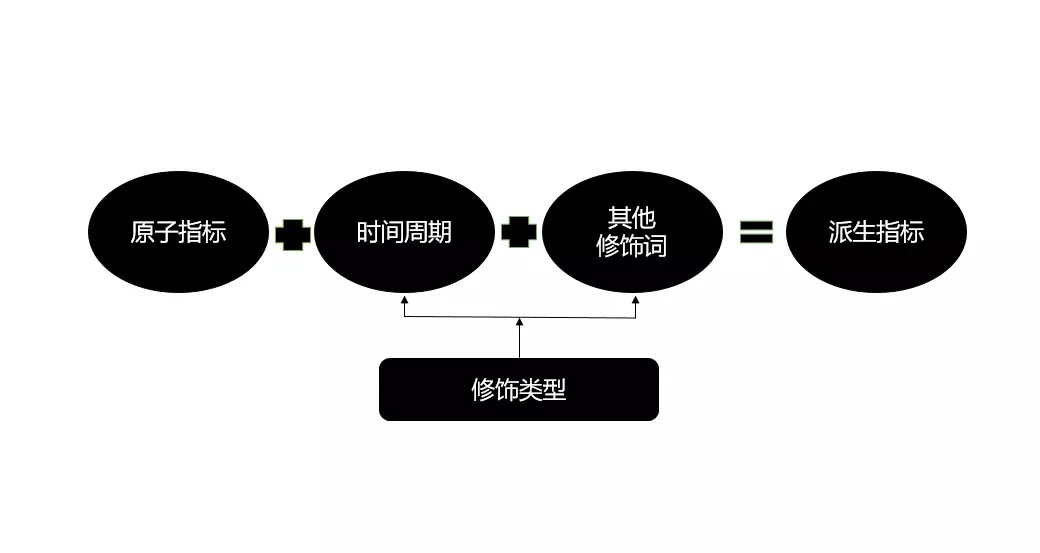
| 派生指标 | 原子指标+修饰词+时间周期就组成了一个派生指标 |
数仓规范一般有哪些呢?
数仓的规范建设一般包括数仓命名规范、开发规范、模型设计规范等,下面进行一下简述,至于具体内容,可以看作者专门的数仓规范篇内容。
数仓命名规范,一般包括数据库命名规范、系统来源命名规范、数据表级字段命名规范、指标命名规范等。
开发规范:一般包括建表规范、作业流规范、数据格式规范、数据字典规范、词根规范、任务注释规范等。
模型设计规范:一致性维度设计规范、事实表设计规范、数仓分层规范、主题域划分规范等。
业务指标的标准化
数仓规范的定义除了指导命名,数据域、业务过程、修饰类型等的定义之外,还有一个重要的目标是管理每个指标,为上层数据产品、应用和服务提供公共指标。
据阿里巴巴公共数据平台负责人介绍,阿里通过对30000多个数据指标进行了口径的规范和统一,梳理后缩减为3000余个,尽管工程浩大,但是此举却为阿里带来了显著的收效。
之所以拆这么彻底,就是要消除歧义。条件允许的话可以协调开发同事、测试同事、产品同事口述一下对这个指标的理解看看有什么不同。最大程度的消除指标的歧义。
最后基于onedata如何构建数据指标这是一个很大的论点和内容,后续作者会单独写一篇文章,进行介绍,欢迎大家关注。
模型设计及开发


数据模型的设计主要还是以维度建模理论为基础,基于维度数据模型总线架构,构建一致性的维度和事实。
知识扩展
在2019年的阿里大会上,结合数据中台概念,阿里对onedata这一定义进行了更新完善更加前面的讲解,细化成OneModel,oneID,OneService。

OneModel 即建立企业统一的数据公共层,从设计、开发、部署和使用上保障了数据口径规范和统一,实现数据资产全链路管理,提供标准数据输出。
OneID 即建立业务实体要素资产化为核心,实现全域链接、标签萃取、立体画像,其数据服务理念根植于心,强调业务模式。
OneService 即数据被整合和计算好之后,需要提供给产品和应用进行数据消费,为了更好的性能和体验,需要构建数据服务层,通过统一的接口服务化方式对外提供数据服务。
总结
OneData 的实施过程是一个高度迭代和动态的过程,一般采用螺旋式实施方法。在总体架构设计完成后,开始根据数据域进行迭代示模型设计和评审。同时在架构设计、规范定义和模型设计等模型实施过程中,都会引入评审机制,以确保模型实施过程的正确性。
这里再强调一下作者对这一体系的总结,onedata 是通过完善的规范定义,同时结合数据中台产品,进行指标的统一定义及梳理,进一步标准化建模,从而保证数据只加工一次。







